Introduction to Likelihood Theory/The Basic Definitions
< Introduction to Likelihood TheoryFormal Probability Review
Let 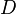 be a set contained in
be a set contained in 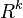 , and
, and 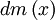 is the counting measure if is discrete, Lebesgue measure if is continuous and Steltjes measure otherwise (if you don't know what a measure function in a
is the counting measure if is discrete, Lebesgue measure if is continuous and Steltjes measure otherwise (if you don't know what a measure function in a  is, lookup in w:measure (mathematics) or just consider that if is continuous the integrals below are the usual integrals from calculus, and the integrals resume to summation over for discrete sets).
is, lookup in w:measure (mathematics) or just consider that if is continuous the integrals below are the usual integrals from calculus, and the integrals resume to summation over for discrete sets).
Definition.: A function 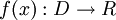 is a probability density function (abbreviated pdf) if and only if
is a probability density function (abbreviated pdf) if and only if
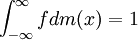
and
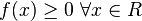 .
.
We say that a variable 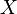 has pdf f if the probability of being in any set
has pdf f if the probability of being in any set 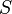 is given by the expression
is given by the expression
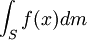
(if you don't know measure theory, consider that is an interval on the real line).
Exercise 1.1 - Show that 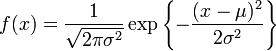 is a pdf with
is a pdf with  ,
, 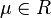 and
and 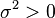 .
.
Exercise 1.2 - Show that we can build a distribution function using the function 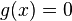 , if
, if 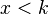 ,
, 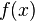 otherwise (
otherwise (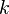 is any real number,
is any real number, 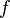 is defined in the previous exercise) by multiplying it with an appropriate constant. Find the constant. Generalize it for any pdf defined on the real line.
is defined in the previous exercise) by multiplying it with an appropriate constant. Find the constant. Generalize it for any pdf defined on the real line.
Exercise 1.3 - If has distribuition with 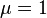 and
and 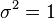 , what is the distribution of the function
, what is the distribution of the function 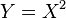 ?(Calculate it, don't look it up on probability books). In statistics, the term probability density function is often abbreviated to density.
?(Calculate it, don't look it up on probability books). In statistics, the term probability density function is often abbreviated to density.
Definition.: Let be a random variable with density . The Cumulative Distribution Function (cdf) of is the function defined as
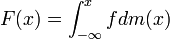
This function is often called distribution function or simply distribution. Since the distribution determines uniquely the density, the terms distribution and density are used by statisticians as synonymous (provided no ambiguity arises from the context).
Exercise 1.4 - Prove that every cdf is nondecreasing.
Definition.: Let be a random variable. We call the expectation of the function 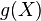 the value
the value
![E[g(X)]=\int_{-\infty}^{\infty}gfdm(x)](../I/m/b56512335fb7985f3169746bd28844ea.png)
where is the density of . The expectation og the identity function is called expectation of .
Exercise 1.5 - Compute the expectation of the random variables defined in Exercise 1.1.
Exercise 1.6 - Show that ![E[c]=c](../I/m/c85c1ce4a42468597566c570c1396e2f.png) for any constant
for any constant  .
.
Exercise 1.7 - Show that ![E[g(x)+c]=E[g(x)]+c](../I/m/e4263f3cd3b218f9d31d281592ecb585.png) for any constant .
for any constant .
In The Beginning There Were Chaos, Empirical Densities and Samples
A population is a collection of objects (collection, not a proper set or class in a Logicist point of view) where each object has an array of measurable variables. Examples include the set of all people on earth together with their heights and weights and the set of all fish in a lake together with artificial marks on them, whre this latter case is found in capture-recapture studies (I suggest you look into Wikipedia and find out what is a capture-recapture study). Let  be an element of a population and
be an element of a population and 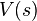 be the array of measurable variables mensured in the object (for an example, is a man and is his height and weight measured at some arbitrary instant, or is a fish and is
be the array of measurable variables mensured in the object (for an example, is a man and is his height and weight measured at some arbitrary instant, or is a fish and is 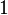 if he has a man-made mark on it and
if he has a man-made mark on it and 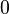 otherwise). A sample of a population
otherwise). A sample of a population 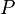 is a collection (again, not a set) where
is a collection (again, not a set) where 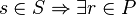 such that
such that 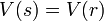 .
.
There are two main methods for generating samples: Sampling with replacement and Sampling without replacement (duh!).
In the former, you randomly select a element 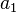 of , and call the set
of , and call the set 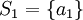 your first subsample. Define you (n+1)-th subsample as the set
your first subsample. Define you (n+1)-th subsample as the set 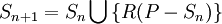 , where
, where 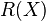 is a function returning a randomly chosen element of . Any subsample you pick generated using the definitions above will be called a sample without replacement, and is the more intuitive kind of sample but also one of the most complicated to obtain in a real world situation. In the former, we have
is a function returning a randomly chosen element of . Any subsample you pick generated using the definitions above will be called a sample without replacement, and is the more intuitive kind of sample but also one of the most complicated to obtain in a real world situation. In the former, we have 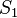 and defined in the same way above, but in this case we have
and defined in the same way above, but in this case we have 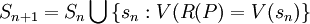 . Samples with replacement have the exquisite property that they have different objects with same characteristics.
. Samples with replacement have the exquisite property that they have different objects with same characteristics.
TODO.: Some stuff on empirical densities and example of real world sampling techniques.
Likelihoods, Finally
Given a random vector ![Y=\left[Y_{1}~Y_{2}~\cdots~Y_{n}\right]^{T}](../I/m/943ff60a05792cbb22ecdec8404a3ff1.png) with density
with density 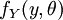 , where
, where 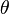 is a vector of parameters, and an observation
is a vector of parameters, and an observation ![y'=\left[y'_{1}~y'_{2}~\cdots~y'_{n}\right]^{T}](../I/m/02e55c487b174dd85aaaaa022e281dd9.png) of
of 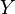 , we define the likelihood function associated with
, we define the likelihood function associated with 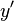 as
as
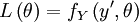
This is a function of , but not of , of an observation 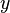 or any other related quantity, for
or any other related quantity, for 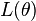 is the restriction of the function
is the restriction of the function 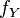 , which is a function of
, which is a function of 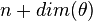 , to a subspace where the are fixed.
, to a subspace where the are fixed.
In many applications we have that, for all 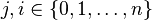 ,
, 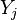 and
and 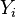 are independent. Suppose that we draw a student from a closed classroom at random, record his height
are independent. Suppose that we draw a student from a closed classroom at random, record his height 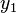 , and put him back. If we repeat the proccess
, and put him back. If we repeat the proccess 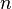 times, the set of heights measured forms an observed vector , and our variable is the distribution of the height of the students in that classroom. Then we have our independence supposition fullfilled, as it will be for any sampling scheme with replacement. In the case where the supposition is true, the above definition of likelihood finction is equivalent to
times, the set of heights measured forms an observed vector , and our variable is the distribution of the height of the students in that classroom. Then we have our independence supposition fullfilled, as it will be for any sampling scheme with replacement. In the case where the supposition is true, the above definition of likelihood finction is equivalent to
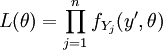
where 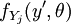 is the probability density function of the variable .
is the probability density function of the variable .
Exercise 3.1: Let 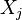 have a Gaussian density with zero mean and unit variance for all
have a Gaussian density with zero mean and unit variance for all 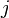 . Compute the likelihood function of
. Compute the likelihood function of 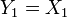 and
and 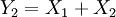 for an arbitrary sample.
for an arbitrary sample.
Intuitive Meaning?
This function we call likelihood is not directly related to the probability of events involving or any proper subset of it, despite its name, but it has a non-obvious relation to the probability of the sample as a whole being selected in the space of all the possible samples. This can be seen if we use discrete densities (or probability generating functions). Supose that each 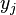 has a binomial distribution with
has a binomial distribution with 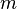 tries and succes probability
tries and succes probability 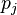 , and they are independent. So the likelihood function associated with a sample
is
, and they are independent. So the likelihood function associated with a sample
is
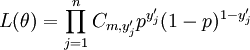
where each 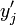 is in
is in 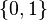 , and
, and 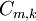 means
means 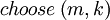 . This function is the probability of this particular sample appear considering all the possible samples of the same size, but this trail of thought only works in discrete cases with finite sample space.
. This function is the probability of this particular sample appear considering all the possible samples of the same size, but this trail of thought only works in discrete cases with finite sample space.
Exercise 4.1: In the Binomial case, does 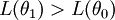 has any probabilistic meaning? If the observed values are throws of regular fair coins, what can you expect of the function ?
has any probabilistic meaning? If the observed values are throws of regular fair coins, what can you expect of the function ?
But the likelihood has a comparative meaning. Supose that we are given two observations of , namely 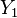 and
and 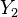 . Then each observation defines a likelihood function, and for each fixed
. Then each observation defines a likelihood function, and for each fixed 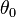 , we may compare their likelihoods
, we may compare their likelihoods 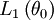 and
and 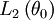 to argue that the one with bigger value occurs more likely. This argument equivalent to Fisher's rant against Inverse Probabilities.
to argue that the one with bigger value occurs more likely. This argument equivalent to Fisher's rant against Inverse Probabilities.
Bayesian Generalization
Even if most classical statisticians (also called "frequentists") complain, we must talk about this generalization of the likelihood function concept. Given that the vector has a density conditional on called 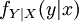 and that we have a observation
and that we have a observation 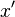 of (I said , forget about observations of in this section!), we will play a little with the function
of (I said , forget about observations of in this section!), we will play a little with the function
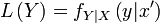
Before anything, Exercise 5.1: Find two tractable discrete densities with known conditional density and compute their likelihood function. Relate 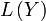 to
to 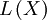 .
.
On to Maximum Likelihood Estimation
Thank you for reading
Some comments are needed. The "?" mark in the previous section title is proposital, to show how this might be confusing. It needs more exercises and examples from outside formal probability. The way this thing is right now needs a good background in formal probability (high level) and much more experience with sampling.