The Linux Kernel/Processing
< The Linux KernelIntroduction
Process management is an integral part of any modern-day operating system. The OS must allocate resources to processes, enable processes to share and exchange information, protect the resources of each process from other processes and enable synchronisation among processes. To meet these requirements, the OS must maintain a data structure for each process, which describes the state and resource ownership of that process, and which enables the OS to exert control over each process.
From the process management point of view, the Linux kernel is a preemptive multitasking operating system. As a multitasking OS, it allows multiple processes to share processors (CPUs) and other system resources. Each CPU executes a single task at a time. However, multitasking allows each processor to switch between tasks that are being executed without having to wait for each task to finish. For that, the kernel can, at any time, temporarily interrupt a task being carried out by the processor, and replace it by another task that can be new or a previously suspended one. The operation involving the swapping of the running task is called context switch.
Since the 2.6 series, Linux multitasking abilities extends also to kernel mode tasks.
Processes and Tasks
Process is a running user space program. Kernel can start a process with function do_execve. Processes occupy system resources, like memory, CPU time. System calls sys_fork and sys_execve are used to create new processes from user space. The process exit with an sys_exit system call.
- API: kthread_run,do_fork,do_execve,
- Implementation: current, task_struct
Process Management Linux API
Linux inherits from Unix its basic process management system calls:
- fork()
- exit()
- wait()
- the exec() family
Linux enhances the traditional Unix process API with its own system calls:
- clone() creates a child process that may share parts of its execution context with the parent. It is often used to implement threads (though programmers will typically use a higher-level interface such as pthreads, implemented on top of clone).
User space API
#include <unistd.h>
pid_t fork(void);
The fork() subroutine creates a new process by duplicating the process invoking it. The new process is referred to as the child and the calling process as the parent.
Upon successful completion, fork() returns a value of 0 to the child process and the value of the new process' PID to the parent process. If it is unsuccessful, a value of −1 is returned and the errno global variable is set to indicate the error.
#include <unistd.h>
void _exit(int status);
The _exit() subroutine terminates the process invoking it and records a status value to be returned to its parent process. This subroutine itself never returns and always success.
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
The wait() subroutine suspends the execution of the calling process until one of its children processes terminates. If the child process ended by a call to _exit(), the parent can retrieve its recorded status value through the status address.
Upon successful completion, wait() returns the process ID of the terminated child. If it is unsuccessful, a value of −1 is returned and the errno global variable is set to indicate the error.
#include <unistd.h>
int execve(const char *filename, char *const argv[], char *const envp[]);
The execve() subroutine runs an executable file in the context of current process, replacing the previous executable.
Upon successful completion, execve() does not return. If it is unsuccessful, a value of −1 is returned and the errno global variable is set to indicate the error.
Linux system calls
The system call prototypes can be found in include/linux/syscalls.h header file:
asmlinkage long sys_fork (void);
asmlinkage long sys_vfork(void);
asmlinkage long sys_clone(unsigned long, unsigned long, int __user *, int __user *, unsigned long);
asmlinkage long sys_exit(int error_code);
asmlinkage long sys_wait4 (pid_t pid, int __user *stat_addr, int options, struct rusage __user *ru);
asmlinkage long sys_waitpid(pid_t pid, int __user *stat_addr, int options);
asmlinkage long sys_execve(const char __user *filename,
const char __user *const __user *argv,
const char __user *const __user *envp);
In Linux there is only one corresponding system call named sys_execve(), whereas all aforementioned exec() functions are user-space wrappers around it.
Process Scheduling
The process scheduler is the part of the operating system that decides which process runs at a certain point in time. It usually has the ability to pause a running process, move it to the back of the running queue and start a new process.
Active processes are placed in an array called a run queue, or runqueue. The run queue may contain priority values for each process, which will be used by the scheduler to determine which process to run next. To ensure each program has a fair share of resources, each one is run for some time period (quantum) before it is paused and placed back into the run queue. When a program is stopped to let another run, the program with the highest priority in the run queue is then allowed to execute. Processes are also removed from the run queue when they ask to sleep, are waiting on a resource to become available, or have been terminated.
In Linux 2.4, an O(n) scheduler with a multilevel feedback queue with priority levels ranging from 0 to 140 was used; 0–99 are reserved for real-time tasks and 100–140 are considered nice task levels. For real-time tasks, the time quantum for switching processes was approximately 200 ms, and for nice tasks approximately 10 ms. The scheduler ran through the run queue of all ready processes, letting the highest priority processes go first and run through their time slices, after which they will be placed in an expired queue. When the active queue is empty the expired queue will become the active queue and vice versa.
In versions 2.6.0 to 2.6.22, the kernel used the O(1) scheduler developed by Ingo Molnár and many other kernel developers during the Linux 2.5 development. In the O(1) scheduler, each CPU in the system is given a run queue, which maintains both an active and expired array of processes. Each array contains 140 (one for each priority level) pointers to doubly linked lists, which in turn reference all processes with the given priority. The scheduler selects the next process from the active array with highest priority. When a process' quantum expires, it is placed into the expired array with some priority. When the active array contains no more processes, the scheduler swaps the active and expired arrays (an operation of O(1) complexity, hence the name).
Since Linux 2.6.23 Ingo Molnár replaced the O(1) scheduler with the Completely Fair Scheduler (CFS), the first implementation of a fair queuing process scheduler widely used in a general-purpose operating system. CFS uses a well-studied, classic scheduling algorithm called "fair queuing" originally invented for packet networks. The CFS scheduler has a scheduling complexity of O(log N), where N is the number of tasks in the runqueue. Choosing a task can be done in constant time, but reinserting a task after it has run requires O(log N) operations, because the run queue is implemented as a red-black tree.
In contrast to the previous O(1) scheduler, the CFS scheduler implementation is not based on run queues. Instead, a red-black tree implements a "timeline" of future task execution. Additionally, the scheduler uses nanosecond granularity accounting, the atomic units by which an individual process' share of the CPU was allocated (thus making redundant the previous notion of timeslices). This precise knowledge also means that no specific heuristics are required to determine the interactivity of a process, for example.
Like the old O(1) scheduler, CFS uses a concept called "sleeper fairness", which considers sleeping or waiting tasks equivalent to those on the runqueue. This means that interactive tasks which spend most of their time waiting for user input or other events get a comparable share of CPU time when they need it.
The data structure used for the scheduling algorithm is a red-black tree in which the nodes are scheduler specific structures, entitled "sched_entity". These are derived from the general task_struct process descriptor, with added scheduler elements. These nodes are indexed by processor execution time in nanoseconds. A maximum execution time is also calculated for each process. This time is based upon the idea that an "ideal processor" would equally share processing power amongst all processes. Thus, the maximum execution time is the time the process has been waiting to run, divided by the total number of processes, or in other words, the maximum execution time is the time the process would have expected to run on an "ideal processor".
When the scheduler is invoked to run a new processes, the operation of the scheduler is as follows:
- The left most node of the scheduling tree is chosen (as it will have the lowest spent execution time), and sent for execution.
- If the process simply completes execution, it is removed from the system and scheduling tree.
- If the process reaches its maximum execution time or is otherwise stopped (voluntarily or via interrupt) it is reinserted into the scheduling tree based on its new spent execution time.
- The new left-most node will then be selected from the tree, repeating the iteration.
If the process spends a lot of its time sleeping, then its spent time value is low and it automatically gets the priority boost when it finally needs it. Hence such tasks do not get less processor time than the tasks that are constantly running.
An alternative to CFS is the Brain Fuck Scheduler (BFS) created by Con Kolivas. The objective of BFS, compared to other schedulers, is to provide a scheduler with a simpler algorithm, that does not require adjustment of heuristics or tuning parameters to tailor performance to a specific type of computation workload.
The Linux kernel contains different scheduler classes (or policies). The Completely Fair Scheduler used nowadays by default is internally known as the SCHED_OTHER scheduler class. The kernel also contains two additional classes SCHED_BATCH and SCHED_IDLE, and another two real-time scheduling classes named SCHED_FIFO (realtime first-in-first-out) and SCHED_RR (realtime round-robin), with a third realtime scheduling policy known as SCHED_DEADLINE that implements the earliest deadline first algorithm (EDF) added later. Any realtime scheduler class takes precedence over any of the "normal" —i.e. non realtime— classes. The scheduler class is selected and configured through the sched_setscheduler() system call.
Wait queues
A wait queue in the kernel is a data structure that allows one or more processes to wait (sleep) until something of interest happens. They are used throughout the kernel to wait for available memory, I/O completion, message arrival, and many other things. In the early days of Linux, a wait queue was a simple list of waiting processes, but various scalability problems (including the thundering herd problem) have led to the addition of a fair amount of complexity since then.
Synchronization
Thread synchronization is defined as a mechanism which ensures that two or more concurrent processes or threads do not simultaneously execute some particular program segment known as mutual exclusion. When one thread starts executing the critical section (serialized segment of the program) the other thread should wait until the first thread finishes. If proper synchronization techniques are not applied, it may cause a race condition where, the values of variables may be unpredictable and vary depending on the timings of context switches of the processes or threads.
For syncronization Linux provides:
- semaphores;
- spinlocks;
- readers–writer locks, for the longer section of codes which are accessed very frequently but don't change very often.
Enabling and disabling of kernel preemption replaced spinlocks on uniprocessor systems. Prior to kernel version 2.6, Linux disabled interrupt to implement short critical sections. Since version 2.6 and later, Linux is fully preemptive.
Spinlocks
a spinlock is a lock which causes a thread trying to acquire it to simply wait in a loop ("spin") while repeatedly checking if the lock is available. Since the thread remains active but is not performing a useful task, the use of such a lock is a kind of busy waiting. Once acquired, spinlocks will usually be held until they are explicitly released, although in some implementations they may be automatically released if the thread being waited on (that which holds the lock) blocks, or "goes to sleep".
Spinlocks are commonly used inside kernels because they are efficient if threads are likely to be blocked for only short periods. However, spinlocks become wasteful if held for longer durations, as they may prevent other threads from running and require rescheduling.
Seqlocks
A seqlock (short for "sequential lock") is a special locking mechanism used in Linux for supporting fast writes of shared variables between two parallel operating system routines. It is a special solution to the readers–writers problem when the number of writers is small.
The semantics stabilized as of version 2.5.59, and they are present in the 2.6.x stable kernel series. The seqlocks were developed by Stephen Hemminger and originally called frlocks, based on earlier work by Andrea Arcangeli. The first implementation was in the x86-64 time code where it was needed to synchronize with user space where it was not possible to use a real lock.
It is a reader-writer consistent mechanism which avoids the problem of writer starvation. A seqlock consists of storage for saving a sequence number in addition to a lock. The lock is to support synchronization between two writers and the counter is for indicating consistency in readers. In addition to updating the shared data, the writer increments the sequence number, both after acquiring the lock and before releasing the lock. Readers read the sequence number before and after reading the shared data. If the sequence number is odd on either occasion, a writer had taken the lock while the data was being read and it may have changed. If the sequence numbers are different, a writer has changed the data while it was being read. In either case readers simply retry (using a loop) until they read the same even sequence number before and after.
Read-Copy-Update
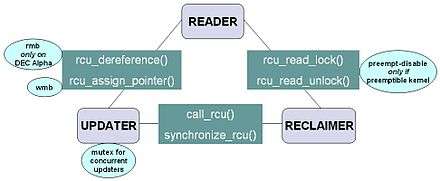
Another synchronization mechanism that solves the readers–writers problem is the read-copy-update (RCU) algorithm. Read-copy-update implementes a kind of mutual exclusion that is wait-free (non-blocking) for readers, allowing extremely low overhead. However, RCU updates can be expensive, as they must leave the old versions of the data structure in place to accommodate pre-existing readers.
RCU was added to Linux in October 2002. Since then, there are almost 9,000 uses of the RCU API within the kernel including the networking protocol stacks and the memory-management system. The implementation of RCU in version 2.6 of the Linux kernel is among the better-known RCU implementations. The core API is quite small:
- rcu_read_lock(): Marks an RCU-protected data structure so that it won't be reclaimed for the full duration of that critical section.
- rcu_read_unlock(): Used by a reader to inform the reclaimer that the reader is exiting an RCU read-side critical section. Note that RCU read-side critical sections may be nested and/or overlapping.
- synchronize_rcu(): It blocks until all pre-existing RCU read-side critical sections on all CPUs have completed. Note that
synchronize_rcuwill not necessarily wait for any subsequent RCU read-side critical sections to complete. For example, consider the following sequence of events:
CPU 0 CPU 1 CPU 2 ----------------- ------------------------- --------------- 1. rcu_read_lock() 2. enters synchronize_rcu() 3. rcu_read_lock() 4. rcu_read_unlock() 5. exits synchronize_rcu() 6. rcu_read_unlock()
- Since
synchronize_rcuis the API that must figure out when readers are done, its implementation is key to RCU. For RCU to be useful in all but the most read-intensive situations,synchronize_rcu's overhead must also be quite small.
- Alternatively, instead of blocking, synchronize_rcu may register a callback to be invoked after all ongoing RCU read-side critical sections have completed. This callback variant is called
call_rcuin the Linux kernel.
- rcu_assign_pointer(): The updater uses this function to assign a new value to an RCU-protected pointer, in order to safely communicate the change in value from the updater to the reader. This function returns the new value, and also executes any memory barrier instructions required for a given CPU architecture. Perhaps more importantly, it serves to document which pointers are protected by RCU.
- rcu_dereference(): The reader uses
rcu_dereferenceto fetch an RCU-protected pointer, which returns a value that may then be safely dereferenced. It also executes any directives required by the compiler or the CPU, for example, a volatile cast for gcc, a memory_order_consume load for C/C++11 or the memory-barrier instruction required by the old DEC Alpha CPU. The value returned byrcu_dereferenceis valid only within the enclosing RCU read-side critical section. As withrcu_assign_pointer, an important function ofrcu_dereferenceis to document which pointers are protected by RCU.
The RCU infrastructure observes the time sequence of rcu_read_lock, rcu_read_unlock, synchronize_rcu, and call_rcu invocations in order to determine when (1) synchronize_rcu invocations may return to their callers and (2) call_rcu callbacks may be invoked. Efficient implementations of the RCU infrastructure make heavy use of batching in order to amortize their overhead over many uses of the corresponding APIs.
- completion - use completion for synchronization task with ISR and task or two tasks.
- #include <linux/completion.h>
- LKD2: Completion Variables
- mutex
- has owner and usage constrains
- more easy to debug then semaphore
- #include <linux/mutex.h>
- spinlock_t, timer_list, wait_queue_head_t
- semaphore - use mutex instead semaphore if possible
- #include <include/linux/semaphore.h>
- atomic operations
Low level kernel synchronization: futex
A futex (short for "fast userspace mutex") is a kernel system call that programmers can use to implement basic locking, or as a building block for higher-level locking abstractions such as semaphores and POSIX mutexes or condition variables.
A futex consists of a kernelspace wait queue that is attached to an aligned integer in userspace. Multiple processes or threads operate on the integer entirely in userspace (using atomic operations to avoid interfering with one another), and only resort to relatively expensive system calls to request operations on the wait queue (for example to wake up waiting processes, or to put the current process on the wait queue). A properly programmed futex-based lock will not use system calls except when the lock is contended; since most operations do not require arbitration between processes, this will not happen in most cases.
The basic operations of futexes are based on only two central operations —WAIT and WAKE— though some futex implementations (depending on the exact version of the Linux kernel) have a few more operations for more specialized cases.
- WAIT (addr, val)
- Checks if the value stored at the address addr is val, and if it is puts the current thread to sleep.
- WAKE (addr, val)
- Wakes up val number of threads waiting on the address addr.
Time and Timers
Interrupts
An interrupt is a signal to the processor emitted by hardware or software indicating an event that needs immediate attention. An interrupt alerts the processor to a high-priority condition requiring the interruption of the current code the processor is executing. The processor responds by suspending its current activities, saving its state, and executing a function called an interrupt handler (or an interrupt service routine, ISR) to deal with the event. This interruption is temporary, and, after the interrupt handler finishes, the processor resumes normal activities.
There are two types of interrupts: hardware interrupts and software interrupts. Hardware interrupts are used by devices to communicate that they require attention from the operating system. For example, pressing a key on the keyboard or moving the mouse triggers hardware interrupts that cause the processor to read the keystroke or mouse position. Unlike the software type, hardware interrupts are asynchronous and can occur in the middle of instruction execution, requiring additional care in programming. The act of initiating a hardware interrupt is referred to as an interrupt request (IRQ).
A software interrupt is caused either by an exceptional condition in the processor itself, or a special instruction in the instruction set which causes an interrupt when it is executed. The former is often called a trap or exception and is used for errors or events occurring during program execution that are exceptional enough that they cannot be handled within the program itself. For example, if the processor's arithmetic logic unit is commanded to divide a number by zero, this impossible demand will cause a divide-by-zero exception, perhaps causing the computer to abandon the calculation or display an error message. Software interrupt instructions function similarly to subroutine calls and are used for a variety of purposes, such as to request services from low-level system software such as device drivers. For example, computers often use software interrupt instructions to communicate with the disk controller to request data be read or written to the disk.
Each interrupt has its own interrupt handler. The number of hardware interrupts is limited by the number of interrupt request (IRQ) lines to the processor, but there may be hundreds of different software interrupts.
Bottom Halves
- tasklet is a softirq, runs in interrupt context, for time critical operations
- API: DECLARE_TASKLET, tasklet_schedule
- implemented with tasklet_struct, HI_SOFTIRQ, TASKLET_SOFTIRQ
- workqueue - works in scheduler context, for delayed operation
- API: DECLARE_WORK, schedule_work
- softirq is internal system facility and should not be used directly. Use tasklet.
Inter-process communication
Inter-process communication (IPC) refers specifically to the mechanisms an operating system provides to allow processes it manages to share data. Methods for achieving IPC are divided into categories which vary based on software requirements, such as performance and modularity requirements, and system circumstances. Linux inherited from Unix the following IPC mechanisms:
- Signals
- Pipes and named pipes (FIFOs)
- Message queues
- Semaphores
- Shared memory
- Unix Sockets
- Memory-mapped files