Structured Query Language/Window functions
< Structured Query LanguageThe window functions discussed on this page are a special and very powerful extension to 'traditional' functions. They compute their result not on a single row but on a set of rows (similar to aggregate functions acting in correlation with a GROUP BY clause). This set of rows - and this is the crucial point - 'moves' or 'slides' over all rows, which are determined by the WHERE clause. This 'sliding window' is called a frame or - in terms of the official SQL standard - the 'window frame'.
Here are some examples:
- A very easy example is a 'sliding window' consisting of the previous, the current and the next row.
- One typical area for the use of window functions are evaluations about arbitrary time series. If you have the time series of market prices of a share, you can easily compute the Moving Average of the last n days.
- Window functions are often used in data warehouse and other OLAP applications. If you have data about sales of all products over a lot of periods within a lot of regions you can compute statistical indicators about the revenues. This evaluations are more powerful than simple
GROUP BY clauses.
In opposite to GROUP BY clauses, where only one output row per group exists, with window functions all rows of the result set retain their identity and are shown.
Syntax
Window functions are listed between the two key words SELECT and FROM at the same place where usual functions and columns are listed. They contain the key word OVER.
-- Window functions appear between the key words SELECT and FROM
SELECT ...,
<window_function>,
...
FROM <tablename>
...
;
-- They consist of three main parts:
-- 1. function type (which is the name of the function)
-- 2. key word 'OVER'
-- 3. specification, which rows constitute the 'sliding window' (partition, order and frame)
<window_function> := <window_function_type> OVER <window_specification>
<window_function_type> := ROW_NUMBER() | RANK() | LEAD(<column>) | LAG(<column>) |
FIRST_VALUE(<column>) | LAST_VALUE(<column>) | NTH_VALUE(<column>, <n>) |
SUM(<column>) | MIN(<column>) | MAX(<column>) | AVG(<column> | COUNT(<column>)
<window_specification> := [ <window_partition> ] [ <window_order> ] [ <window_frame> ]
<window_partition> := PARTITION BY <column>
<window_order> := ORDER BY <column>
<window_frame> := see below
Overall Description
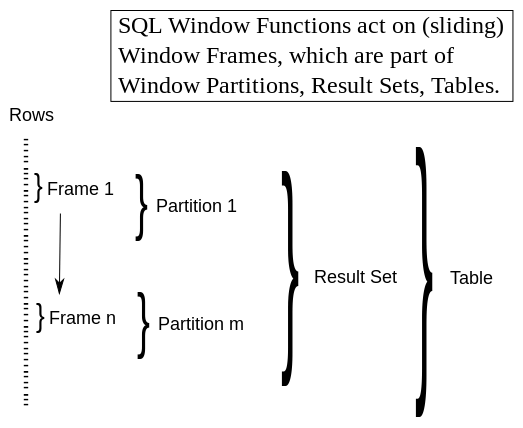
Concerning window functions there are some similar concepts. In order to be able to significantly differ the concepts from each other, it is necessary to use an exact terminology. This terminology is introduced in the next 8 paragraphs, which also - roughly - reflect the order of execution. The goal of the first seven steps is the determination of the actual frame and the eighth step acts on it.
- The
WHERE clausereturns a certain number of rows. They constitutes the result set. - The
ORDER BY clause(syntactically behind theWHERE clause) re-orders the result set into a certain sequence. - This sequence determines the order in which the rows are passed to the
SELECT clause. The row, which is actually given to theSELECT clause, is called the current row. - The
WINDOW PARTITION clausedivides the result set into window partitions (We will use the shorter term partition as in the context of our site there is no danger of confusion). If there is noWINDOW PARTITION clause, all rows of the result set constitutes one partition. (This partitions are equivalent to groups created by theGROUP BY clause.) Partitions are distinct from each other: there is no overlapping as every row of the result set belongs to one and only one partition. - The
WINDOW ORDER clauseorders the rows of each partition (which may differ from theORDER BY clause). - The
WINDOW FRAME clausedefines which rows of the actual partition belong to the actual window frame (We will use the shorter term frame). The clause defines one frame for every row of the result set. This is done by determine the lower and upper boundary of affected rows. In consequence there are as many (mostly different) frames as number of rows in the result set. The upper and lower boundaries are newly determinded with every row of the result set! Single rows may be part of more than one frame. The actual frame is the instanciation of the 'sliding window'. Its rows are ordered according to theWINDOW ORDER clause. - If there is no
WINDOW FRAME clause, the rows of the actual partition constitute frames with the following default boundaries: The first row of the actual partition is their lower boundary and the current row is their upper boundary. If there is noWINDOW FRAME clauseand noWINDOW ORDER clause, the upper boundary switches to the last row of the actual partition. Below we will explain how to change this default behaviour. - The <window_function_type>s act on the rows of the actual frame.
Example Table
We use the following table to demonstrate window functions.
CREATE TABLE employee (
-- define columns (name / type / default value / column constraint)
id DECIMAL PRIMARY KEY,
emp_name VARCHAR(20) NOT NULL,
dep_name VARCHAR(20) NOT NULL,
salary DECIMAL(7,2) NOT NULL,
age DECIMAL(3,0) NOT NULL,
-- define table constraints (it's merely an example table)
CONSTRAINT empoyee_uk UNIQUE (emp_name, dep_name)
);
INSERT INTO employee VALUES ( 1, 'Matthew', 'Management', 4500, 55);
INSERT INTO employee VALUES ( 2, 'Olivia', 'Management', 4400, 61);
INSERT INTO employee VALUES ( 3, 'Grace', 'Management', 4000, 42);
INSERT INTO employee VALUES ( 4, 'Jim', 'Production', 3700, 35);
INSERT INTO employee VALUES ( 5, 'Alice', 'Production', 3500, 24);
INSERT INTO employee VALUES ( 6, 'Michael', 'Production', 3600, 28);
INSERT INTO employee VALUES ( 7, 'Tom', 'Production', 3800, 35);
INSERT INTO employee VALUES ( 8, 'Kevin', 'Production', 4000, 52);
INSERT INTO employee VALUES ( 9, 'Elvis', 'Service', 4100, 40);
INSERT INTO employee VALUES (10, 'Sophia', 'Sales', 4300, 36);
INSERT INTO employee VALUES (11, 'Samantha','Sales', 4100, 38);
COMMIT;
A First Query
The example demonstrates how the boundaries 'slides' over the result set. Doing so, they create one frame after the next, one per row of the result set. These frames are part of partitions, the partitions are part of the result set and the result set is part of the table.
SELECT id,
emp_name,
dep_name,
-- The functions FIRST_VALUE() and LAST_VALUE() explain itself by their name. They act within the actual frame.
FIRST_VALUE(id) OVER (PARTITION BY dep_name ORDER BY id) AS frame_first_row,
LAST_VALUE(id) OVER (PARTITION BY dep_name ORDER BY id) AS frame_last_row,
COUNT(*) OVER (PARTITION BY dep_name ORDER BY id) AS frame_count,
-- The functions LAG() and LEAD() explain itself by their name. They act within the actual partition.
LAG(id) OVER (PARTITION BY dep_name ORDER BY id) AS prev_row,
LEAD(id) OVER (PARTITION BY dep_name ORDER BY id) AS next_row
FROM employee;
-- For simplification we use the same PARTITION and ORDER definitions for all window functions.
-- This not necessary. You can use divergent definitions!
Please notice how the lower boundary (FRAME_FIRST_ROW) and the upper boundary (FRAME_LAST_ROW) changes from row to row.
| ID | EMP_NAME | DEP_NAME | FRAME_FIRST_ROW | FRAME_LAST_ROW | FRAME_COUNT | PREV_ROW | NEXT_ROW |
|---|---|---|---|---|---|---|---|
| 1 | Matthew | Management | 1 | 1 | 1 | - | 2 |
| 2 | Olivia | Management | 1 | 2 | 2 | 1 | 3 |
| 3 | Grace | Management | 1 | 3 | 3 | 2 | - |
| 4 | Jim | Production | 4 | 4 | 1 | - | 5 |
| 5 | Alice | Production | 4 | 5 | 2 | 4 | 6 |
| 6 | Michael | Production | 4 | 6 | 3 | 5 | 7 |
| 7 | Tom | Production | 4 | 7 | 4 | 6 | 8 |
| 8 | Kevin | Production | 4 | 8 | 5 | 7 | - |
| 10 | Sophia | Sales | 10 | 10 | 1 | - | 11 |
| 11 | Samantha | Sales | 10 | 11 | 2 | 10 | - |
| 9 | Elvis | Service | 9 | 9 | 1 | - | - |
The query has no WHERE clause. Therefore all rows of the table are part of the result set. According to the WINDOW PARTITION clause, which is 'PARTITION BY dep_name', the result set is divided into the 4 partitions: 'Management', 'Production', 'Sales' and 'Service'. The frames run within these partions. As there is no WINDOW FRAME clause the frames start at the first row of the actual partition and runs up to the current row.
You can see that the actual number of rows within a frame (column FRAME_COUNT) grows from 1 up to the sum of all rows within the partition. When the partition switches to the next one, the number starts again with 1.
The columns PREV_ROW and NEXT_ROW shows the ids of the previous and next row within the actual partition. As the first row has no predecessor, the NULL indicator is shown. This applies correspondingly to the last row and its successor.
Basic Window Functions
We present some of the <window_function_type> functions and their meaning. The standard as well as most implementations knows a lot of additional functions and overloaded variants.
| Signature | Scope | Meaning / Return Value |
|---|---|---|
| FIRST_VALUE(<column>) | Actual Frame | The column value of the first row within the frame. |
| LAST_VALUE(<column>) | Actual Frame | The column value of the last row within the frame. |
| LAG(<column>) | Actual Partition | The column value of the predecessor row (the row which is before the current row). |
| LAG(<column>, <n>) | Actual Partition | The column value of the n.-th row before the current row. |
| LEAD(<column>) | Actual Partition | The column value of the successor row (the row which is after the current row). |
| LEAD(<column>, <n>) | Actual Partition | The column value of the n.-th row after the current row. |
| ROW_NUMBER() | Actual Frame | A numeric sequence of the row within the frame. |
| RANK() | Actual Frame | A numeric sequence of the row within the frame. Identical values in the specified order evaluate to the same number. |
| NTH_VALUE(<column>, <n>) | Actual Frame | The column value of the n.-th row within the frame. |
| SUM(<column>) MIN(<column>) MAX(<column>) AVG(<column>) COUNT(<column>) | Actual Frame | As usual. |
Here are some examples:
SELECT id,
emp_name,
dep_name,
ROW_NUMBER() OVER (PARTITION BY dep_name ORDER BY id) AS row_number_in_frame,
NTH_VALUE(emp_name, 2) OVER (PARTITION BY dep_name ORDER BY id) AS second_row_in_frame,
LEAD(emp_name, 2) OVER (PARTITION BY dep_name ORDER BY id) AS two_rows_ahead
FROM employee;
| ID | EMP_NAME | DEP_NAME | ROW_NUMBER_IN_FRAME | SECOND_ROW_IN_FRAME | TWO_ROWS_AHEAD |
|---|---|---|---|---|---|
| 1 | Matthew | Management | 1 | - | Grace |
| 2 | Olivia | Management | 2 | Olivia | - |
| 3 | Grace | Management | 3 | Olivia | - |
| 4 | Jim | Production | 1 | - | Michael |
| 5 | Alice | Production | 2 | Alice | Tom |
| 6 | Michael | Production | 3 | Alice | Kevin |
| 7 | Tom | Production | 4 | Alice | - |
| 8 | Kevin | Production | 5 | Alice | - |
| 10 | Sophia | Sales | 1 | - | - |
| 11 | Samantha | Sales | 2 | Samantha | - |
| 9 | Elvis | Service | 1 | - | - |
The three example shows:
- The row number within the actual frame.
- The employee name of the second row within the actual frame. This is not possible in all cases. a) Every first frame within the series of frames of a partition consists of only 1 row. b) The last partition and its one and only frame has only one row.
- The employee name of the row which is two rows 'ahead' of the current row. Similar as in the previous column this not possible in all cases.
- Please notice the difference in the last two columns of the first row. The SECOND_ROW_IN_FRAME-column contains the NULL indicator. The frame which is associated with this row contains only 1 row (from the first to the current row) - and the scope of the nth_value() function is 'frame'. In contrast, the TWO_ROW_AHEAD-column contains the value 'Grace'. This value is evaluated by the lead() function, whose scope is the partition! The partition contains 3 rows: all rows within the department 'Management'. Only with the second and third row it becomes impossible to go 2 rows 'ahead'.
Determine Partition and Sequence
As shown in the above examples, the WINDOW PARTITION clause defines the partitions by using the key words PARTITION BY and the WINDOW ORDER clause defines the sequence of rows within the partition by using the key words ORDER BY.
Determine the Frame
The frames are defined by the WINDOW FRAME clause, which optionally follows the WINDOW PARTITION clause and the WINDOW ORDER clause.
With the exception of the lead() and lag() functions, whose scope is the actual partition, all other window functions act on the actual frame. Therefore it is an elementary decision, which rows shall constitute the frame. This is done by establishing the lower and upper boundary (in the sense of the WINDOW ORDER clause). All rows within this two bounds constitute the actual frame. Therefore the WINDOW FRAME clause consists mainly of the definition of the two boundaries - in one of four ways:
- Define a certain number of rows before and after the current row. This leads to a constant number of rows within the series of frames - with some exceptions near the lower and upper boundary and the exception of the use of the 'UNBOUNDED' key word.
- Define a certain number of groups before and after the current row. Such groups are build by the unique values of the preceding and following rows - in the same way as a
SELECT DISTINCT ...orGROUP BY. The resulting frame covers all rows, whose values fall into one of the groups. As every group may be build out of multiple rows (with the same value), the number of rows per frame is not constant. - Define a range for the values of a certain column by denoting a fix numerical value, eg: 1.000 (for a salary) or 30 days (for a time series). The thereby defined range runs from the differenz of the current value and the defined value up to the current value (the FOLLOWING-case builds the sum, not the differenz). All rows of the partition, whose column values fall into this range, constitute the frame. Accordingly the number of rows within the frame may differ from frame to frame - in opposite to the rows technic.
- Omit the clause and use default values.
In accordance with this different strategies there are three key words 'ROWS', 'GROUPS' and 'RANGE' which leads to the different behaviour.
Terminology
The WINDOW FRAME clause uses some key words whose semantic hopefully gets clear in the following block, where the ordered rows of a partition are visualised.
Rows in a partition and the according key words - <-- UNBOUNDED PRECEDING (first row) ... - <-- 2 PRECEDING - <-- 1 PRECEDING - <-- CURRENT ROW - <-- 1 FOLLOWING - <-- 2 FOLLOWING ... - <-- UNBOUNDED FOLLOWING (last row)
The term UNBOUNDED PRECEDING denotes the first row in a partition and UNBOUNDED FOLLOWING the last row. Counting from the CURRENT ROW there are <n> PRECEDING and <n> FOLLOWING rows. Obviously this PRECEDING/FOLLOWING terminology works only, if there is a WINDOW ORDER clause which creates an unambiguous sequence.
The (simplified) syntax of the WINDOW FRAME clause is:
<window_frame> := [ROWS | GROUPS | RANGE ] BETWEEN
[ UNBOUNDED PRECEDING | <n> PRECEDING | CURRENT ROW ] AND
[ UNBOUNDED FOLLOWING | <n> FOLLOWING | CURRENT ROW ]
An example of a complete window function with its WINDOW FRAME clause is:
...
SUM(salary) OVER (PARTITION BY dep_name ORDER BY salary
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as growing_sum,
...
In this case the WINDOW FRAME clause starts with the key word 'ROWS'. It defines the lower boundary to the very first row of the partition and the upper boundary to the actual row. This means that the series of frames grows from frame to frame by one additional row until all rows of the partition are handled. Afterwards the next partition starts with an 1-row-frame and repeats the growing.
ROWS
The ROWS syntax defines a certain number of rows to process.
SELECT id, dep_name, salary,
SUM(salary) OVER (PARTITION BY dep_name ORDER BY salary
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum_over_1or2or3_rows
FROM employee;
The example acts on a certain number of rows, namely the two rows before the current row (if existing within the partition) and the current row. There is no situation where more than three rows exists in one of the frames. The window function computes the sum of the salary over these maximal three rows.
The sum is reset to zero with every new partition, which is the department in this case. This holds true also for the GROUPS and RANGE syntax.
The ROWS syntax is often used when one is interested in the average about a certain number of rows or in the distance between two rows.
GROUPS
The GROUPS syntax has a similar semantic as the ROWS syntax - with one exception: rows with equal values within the column of the WINDOW ORDER clause count as 1 row. With other words, the GROUPS sytax counts the number of distinct values, not the number of rows.
-- Hint: The syntax 'GROUPS' (Feature T620) is not supported by Oracle 11
SELECT id, dep_name, salary,
SUM(salary) OVER (PARTITION BY dep_name ORDER BY salary
GROUPS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS sum_over_groups
FROM employee;
The example starts with the key word GROUPS and defines that it wants to work on 3 distinct values of the column 'salary'. Possibly there are more than three rows satisfying this criteria - in opposite to the equivalent ROWS strategy.
The GROUPS syntax is the appropriate strategy, if one has a varying number of rows within the time period under review, eg.: one has a varying number of measurement values per day and is interested in the average or the variance over a week or month.
RANGE
At a first glance the RANGE syntax is similar to the ROWS and GROUPS syntax. But the semantic is very different! Numbers <n> given in this syntax did not specify any counter. They specify the distance from the value in the current row to the lower or upper boundary. Therefor the ORDER BY column shall be of type NUMERIC, DATE or INTERVAL.
SELECT id, dep_name, salary,
SUM(salary) OVER (PARTITION BY dep_name ORDER BY salary
RANGE BETWEEN 100 PRECEDING AND 50 FOLLOWING) AS sum_over_range
FROM employee;
This definition leads to the sum over all rows which have a salary from 100 below and 50 over the actual row. In our example table this criteria appies in some rare cases to more than 1 row.
Typical use cases for the RANGE strategy are situations where someone analyzes a wide numeric range and expects to meet only few rows within this range, e.g.: a sparse matrix.
Defaults
If the WINDOW FRAME clause is omitted, its default value is: 'RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW'. This leads to a range from the very first row of the partition up the current row plus all rows with the same value as the current row - because the RANGE syntax applies.
If the WINDOW ORDER clause is omitted, the WINDOW FRAME clause is not allowed and all rows of the partition constitute the frame.
If the PARTITION BY clause is omitted, all rows of the result set constitues the one and only partition.
A Word of Caution
Although the SQL standard 2003 and his successors define very clear rules concerning window functions, several implementations did not follow them. Some implement only parts of the standard - which is their own responsibility -, but others seems to interpret the standard in a fanciful fashion.
As far we know, the ROWS syntax is implemented standard conform - if it is implemented. But it seems that the RANGE syntax sometimes implements what the GROUPS syntax of the SQL standard requires. (Perhaps this is a misrepresentation and only the public available descriptions of various implementations does not reflect the details.) So: be carefull, test your system and give us a feedback on the discussion page.
Exercises
Show id, emp_name, dep_name, salary and the average salary within the department.
--
-- To get the average of the department, every frame must be build by ALL rows of the department.
--
SELECT id, emp_name, dep_name, salary,
avg(salary) OVER (PARTITION BY dep_name ORDER BY dep_name
-- all rows of partition (=department)
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as avg_salary
FROM employee;
--
-- It's possible to omit the 'window order' clause. Thereby the frames include ALL rows of the actual partition.
-- See: 'Defaults' above.
--
SELECT id, emp_name, dep_name, salary,
avg(salary) OVER (PARTITION BY dep_name) as avg_salary
FROM employee;
--
-- The following statements leads to different results as the frames are composed by a growing number of rows.
--
SELECT id, emp_name, dep_name, salary,
avg(salary) OVER (PARTITION BY dep_name ORDER BY salary) as avg_salary
FROM employee;
--
-- It's possible to sort the result set by arbitrary rows (test the emp_name, it's interesting)
--
SELECT id, emp_name, dep_name, salary,
avg(salary) OVER (PARTITION BY dep_name) as avg_salary
FROM employee
ORDER BY dep_name, salary;
Does older persons earn more money than younger?
To give an answer show id, emp_name, salary, age and the average salary of 3 (or 5) persons, which are in a similar age.
SELECT id, emp_name, salary, age,
AVG(salary) OVER ( ORDER BY age ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS mean_over_3,
AVG(salary) OVER ( ORDER BY age ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS mean_over_5
FROM employee;
-- As there is no restriction to any other criterion than the age (department or something else), there is
-- no need for any PARTITION definition. Averages are computed without any interruption.
Extend the above question and its solution to show the results within the four departments.
SELECT id, emp_name, salary, age, dep_name,
AVG(salary) OVER (PARTITION BY dep_name ORDER BY age ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS mean_over_3,
AVG(salary) OVER (PARTITION BY dep_name ORDER BY age ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS mean_over_5
FROM employee;
-- Averages are computed WITHIN departments.
Show id, emp_name, salary and the difference to the salary of the previous person (in ID-order).
-- For mathematician: This is a very first approximation to first derivate.
SELECT id, emp_name, salary,
salary - LAG(salary) OVER (ORDER BY id) as diff_salary
FROM employee;
-- And the difference of differences:
SELECT id, emp_name, salary,
(LAG(salary) OVER (ORDER BY id) - salary) AS diff_salary_1,
(LAG(salary) OVER (ORDER BY id) - salary) -
(LAG(salary, 2) OVER (ORDER BY id) - LAG(salary) OVER (ORDER BY id)) AS diff_salary_2
FROM employee;
Show the 'surrounding' of a value: id and emp_name of all persons ordered by emp_name. Supplement each row with the two emp_names before and the two after the actual emp_name (in the usual alphabetical order).
SELECT id,
LAG(emp_name, 2) OVER (ORDER BY emp_name) AS before_prev,
LAG(emp_name) OVER (ORDER BY emp_name) AS prev,
emp_name AS act,
LEAD(emp_name) OVER (ORDER BY emp_name) AS follower,
LEAD(emp_name, 2) OVER (ORDER BY emp_name) AS behind_follower
FROM employee
ORDER BY emp_name;