PostgreSQL/Architecture
< PostgreSQLThe daily work as a PostgreSQL DBA is based on the knowledge of PostgreSQL's architecture: strategy, processes, buffers, files, configration, backup and recovery, replication, and a lot more. The page on hand describes the most basic concepts.
Introduction
PostgreSQL is a relational database management system with a client-server architecture. At the server side the PostgreSQL's processes and shared memory work together and build an instance, which handles the accesses to the data. Client programs connect oneself to the instance and request read and write operations.
The Instance
The instance always consists of multiple processes. PostgreSQL does not use a multi-threaded model:
- postmaster process
- Multiple postgres processes, one for each connection
- WAL writer process
- background writer process
- checkpointer process
- autovacuum launcher process (optional)
- logger process (optional)
- archiver process (optional)
- stats collector process (optional)
- WAL sender process (if Streaming Replication is active)
- WAL receiver process (if Streaming Replication is active)
- background worker processes (if a query gets parallelised, which is available since 9.6)
How Data is processed
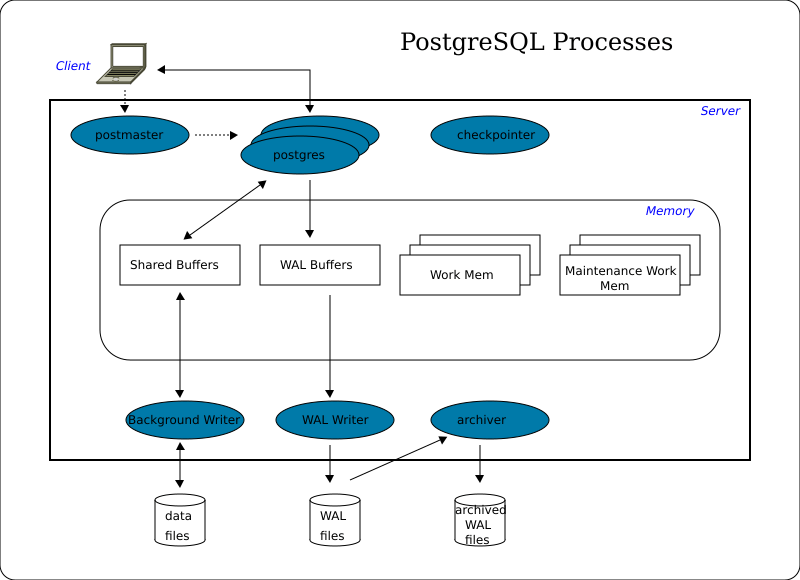
Connecting to the Instance
Client applications, which run on a different server than the instance, use the IP protocoll to connect to it. If client application and instance run on the same server, the same connection method is possible. But it is also possible to use a conncetion via a local socket.
In a first step the application connects to the postmaster process. The postmaster checks the application's rights and - if successful - starts a new postgres process and connects it with the client application.
Accessing Data
Client processes send and request data to and from the instance. For performance reasons, the instance doesn't write or read the requested data directly to or from disk files. Instead, it buffers them in a shared memory area which is called the shared buffers. The flushing to disc is done at a later stage.
To perform a client request, the corresponding postgres process acts on the shared buffers and WAL buffers and manipulates their contents. When the client requests a COMMIT, the WAL writer process writes and flushes all WAL records resulting from this transaction to the WAL file. As the WAL file - in contrast to the data files - is written strictly sequentially, this operation is relatively fast. After that, the client gets its COMMIT confirmation. At this point, the database is inconsistent, which means that there are differences between shared buffers and the corresponding data files.
Periodically the background writer process checks the shared buffers for 'dirty' pages and writes them to the appropriate data files. 'Dirty' pages are those whose content was modified by one of the postgres processes after their transfer from disk to memory.
The checkpointer process also runs periodically, but less frequently than the background writer. When it starts, it prevents further buffer modifications, forces the background writer process to write and flush all 'dirty' pages, and forces the WAL writer to write and flush a CHECKPOINT record to the WAL file after which the database is consistent, which means: a) the content of the shared buffers is the same as the data in the files, b) all modifications of WAL buffers are written to WAL files, and c) table data correlates with index data. This consistency is the purpose of checkpoints.
In essence the instance contains at least the three processes WAL writer, background writer, and checkpointer - and one postgres process per connection. In most cases there are some more processes running.
Optional Processes
The autovacuum launcher process starts a few number of worker processes, which removes superflous row versions according to the MVCC architecture of PostgreSQL. This work is done in shared memory and the 'dirty' pages are written to disc in the same way as such, which results from write requests of other clients.
The logger process writes log, warning, and error messages to a log file (not to the WAL file!).
The archiver process copies WAL files, which are completely filled by the WAL writer, to a configurable location for mid-term storing.
The stats collector process continuously collects information about the number of accesses to tables and indices, total number of rows in tables, and works in coordination with VACUUM/ANALYZE and ANALYZE.
The WAL sender and WAL receiver processes are part of the Streaming Replication feature. They exchange data about changes in the master server bypassing the WAL files on disc.
Since version 9.6 it is possible to execute queries in parallel on several CPUs. In this case those parts of the execution plan, which shall run in parallel, are executed by additional background worker processes. They have access to the shared buffers in the same way as the original postgres processes and handle different buffer pages at the same time.
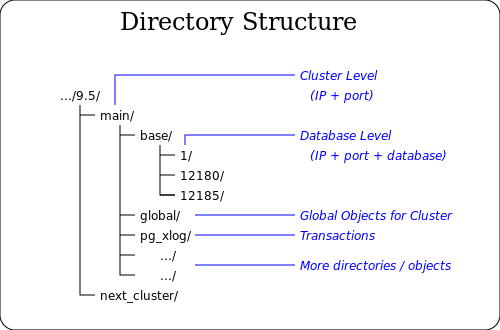
The Directory Structure
Within a cluster there is a fix structure of subdirectories and files. At last all information is stored within these files. Some information contains to the cluster at all, and some belongs to single databases - especially tables and indexes.